
Build Your Own Private RAG Knowledge Base
A fully functional RAG system that sends zero bytes to external services

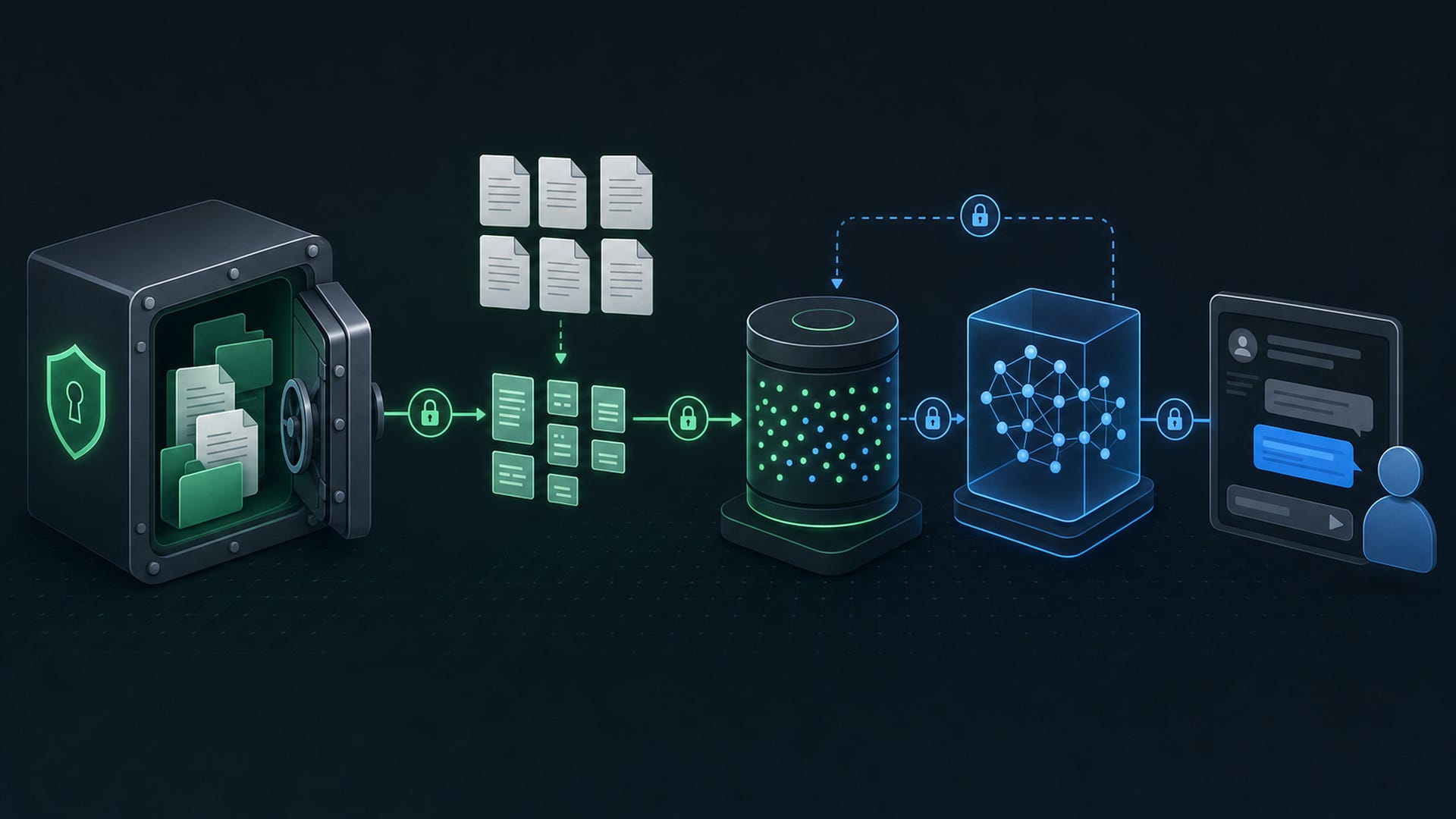
Every query you send to a cloud RAG service leaves your perimeter. Your documents, your questions, your retrieved context, all of it traverses networks you control, stored on servers you trust, accessible to compliance teams you have yet to meet. The convenience is seductive and the cost is invisible until it becomes painfully visible. Bastion builds differently: your knowledge base stays on your hardware, your embeddings stay local, and your audit trail stays complete. This article gives you the architecture and the tooling to run Retrieval Augmented Generation entirely on your own terms.
The Idea (60 Seconds)
RAG augments a language model with retrieved context from your own documents. The typical pipeline ships your data to a cloud vector database and calls a remote embedding API for every query. A private RAG system replaces every cloud dependency with a local equivalent:
Storage and embeddings: Run models like
all-MiniLM-L6-v2orbge-large-en-v1.5locally viasentence-transformers, stored in SQLite with a cosine similarity function. Zero external database server dependencies.Chunking: Split documents with fixed-size overlap, semantic boundaries, or markdown-aware strategies.
Generation: Route prompts to a local LLM through Ollama, llama.cpp, or any local inference engine.
Audit trail: Log every query and every retrieved chunk to a SQLite table. Compliance becomes a SQL query.
The result is a fully functional RAG system that sends zero bytes to external services.
Why This Matters
Privacy is a constraint that sharpens design. When you eliminate cloud dependencies, you also eliminate latency from network round trips, vendor lock-in from proprietary APIs, and data exposure from third-party processing. Your compliance team can audit the entire query history with a single SQL statement. Your security team can verify that zero data leaves the network perimeter. Your finance team can predict costs exactly, because local compute has a fixed price.
Regulated industries , healthcare, legal, defense, finance , operate under data residency rules. Sending patient records or classified documents through an external embedding API violates those rules by design. A private RAG system satisfies the rules by architecture, by policy, or by procedural override. The architecture itself enforces the boundary.
Performance improves too. Local embeddings on a modern GPU or Apple Silicon reach hundreds of embeddings per second. SQLite handles millions of vectors with sub-millisecond lookups when you pre-filter by collection. The bottleneck shifts from network latency to disk I/O, which you control entirely.
